Validating AI where it’s used
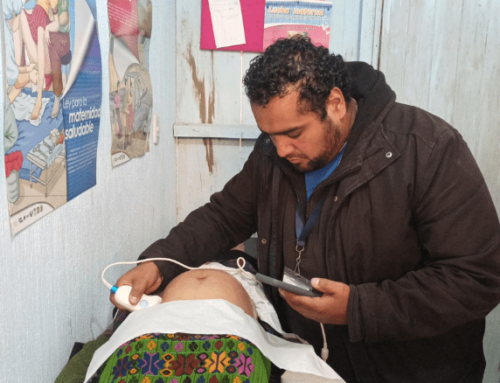
BabyChecker is designed for antenatal care settings with limited access to infrastructure, internet, and clinical specialists. It enables pregnancy risk screening using a handheld ultrasound probe and a mobile phone, operated by a midwife or community health worker. Because BabyChecker operates offline and on Android devices, its AI models must be validated in the same environment in which they are deployed.
While most AI validation is performed on Linux-based workstations using standard datasets, BabyChecker’s approach recognizes a key operational truth: accuracy on a server does not guarantee accuracy on a mobile phone. To deliver clinically safe predictions for gestational age, fetal presentation, and placenta location, BabyChecker’s models are tested and validated directly within Android.
Identifying discrepancies between development and deployment
Our deep learning engineering team compares Android inference outputs to Linux-based references during validation cycles. In doing so, they encountered slight but consistent differences in prediction values, despite using the same input data. Investigation revealed the cause: different image preprocessing libraries produced slight pixel-level variations. Although small, these changes were enough to alter AI output in a way that crossed clinical relevance thresholds.
This phenomenon is consistent with chaos theory, where minimal changes in initial conditions produce unpredictable downstream effects. In AI, such effects cause adversarial errors, even when logical pipelines appear identical.
Aligning pipelines and enforcing consistency
To address this, preprocessing workflows were standardized across platforms using OpenCV. This ensured that images passed to the AI model on Android would match those seen during training and validation in Linux.
To monitor ongoing consistency, the team developed unit tests that:
- Accept raw ultrasound frames
- Apply standardized preprocessing
- Run inference on-device
- Compare predictions to validated reference results
The tests are performed on real Android devices, covering multiple cases from the BabyChecker validation set.
Running complete validation sets on Android
Beyond unit tests, BabyChecker supports complete validation of its AI models in real-world conditions. Engineers import raw scan data and run inference locally across entire validation and test sets through a developer mode in the mobile application. The resulting predictions are exported in JSON format and evaluated for accuracy, sensitivity, specificity, and mean absolute error.
This approach ensures transparency and performance consistency in the environments that matter most: remote clinics, community health posts, and mobile outreach settings.
Metrics that matter
BabyChecker’s AI has been validated on a multicountry dataset spanning Kenya, Zambia, Malawi, and Honduras. When compared with expert sonographers, the results showed:
- Gestational Age: Mean Absolute Error of 5.58 days
- Fetal Presentation: AUC of 0.99
- Placenta Localization: AUC of 0.93
These values confirm the model’s ability to provide clinically practical guidance in settings where standard ultrasound is unavailable and the alternative is often limited to abdominal palpation.
Conclusion
Deploying AI for maternal health in low-resource environments requires more than model accuracy on paper. It requires on-device validation, consistent performance, and technical reliability under real-world conditions. BabyChecker meets this requirement by aligning its AI development with its operational context, validating models on Android, in the field, and in the hands of the health workers it is designed to support.